User Guide
Regular Expression Engine
Remember that the regular expression engine that is used is Python's Re, not Sublime's internal regular expression engine. If enabling extended_back_references, additional syntax (and some changes to existing syntax) is added which is covered in the backrefs documentation.
To enable such features as case insensitivity or dotall, see Re's documentation. If you've enabled the use of the Regex library, see Regex's documentation.
Please note in the documentation the slight syntax differences in each regular expression library. Regex and Backrefs (with Regex or Re) handles things like r'\u0057' in a replace template and converts it to Unicode, while Re will not and requires something like "\u0057" to represent Unicode (note that one is using Python raw strings and the other is not). What this means in respect to RegReplace is that for Re you may have to use actual Unicode characters or represent Unicode in the JSON settings file differently; for Regex, you can use "\\u0057", and in Re you will have to use "\u0057" (JSON's notation for a literal Unicode character). There is one exception with Regex though: "format" replace (without Backrefs) will not handle "\\u0057", and it will not handle "\\n", but will also need literal characters like "\u0057" and "\n".
Create Find and Replace Sequences
In order to use them, replacements must be defined in the reg_replace_rules.sublime-settings file.
There are two types of rules that can be created: scope rules (with optional scope qualifiers) and scope searches that apply regular expressions to the targeted scopes. We will call these regex and scope regex rules respectively.
Regex rules use regular expressions to find regions, and then you can use scopes to qualify the regions before applying the replacements. These rules can use the following options:
/*
###### Regex with optional scope qualifiers. ######
- find (required)
- replace
- literal
- literal_ignorecase
- greedy
- scope_filter
- format_replace
- selection_inputs
- plugin
- args
*/
{
"replacements": {
"html5_remove_deprecated_type_attr": {
"find": "(?i)(<(style|script)[^>]*)\\stype=(\"|')text/(css|javascript)(\"|')([^>]*>)",
"replace": "\\1\\6",
"greedy": true
},
The second kind of rule is the scope regex which allows you to search for a scope type and then apply regular expression to the regions to filter the matches and make replacements.
/*
###### Scope search with regular expression applied to scope region. ######
- scope (required)
- find
- replace
- literal
- literal_ignorecase
- greedy
- greedy_scope
- format_replace
- multi_pass
- selection_inputs
- plugin
- args
*/
{
"replacements": {
"remove_comments": {
"scope": "comment",
"find" : "(([^\\n\\r]*)(\\r\\n|\\n))*([^\\n\\r]+)",
"replace": "",
"greedy": true,
"greedy_scope": true
}
A description of all the options is found below:
name: (str): Rule name. Required.
find: (str): Regular expression pattern or literal string.
Use (?i) for case insensitive. Use (?s) for dotall.
See https://docs.python.org/3.4/library/re.html for more info on regex flags.
Required unless "scope" is defined.
replace: (str - default=r'\g<0>'): Replace pattern.
literal: (bool - default=False): Perform a non-regex, literal search and replace.
literal_ignorecase: (bool - default=False): Ignore case when "literal" is true.
scope: (str): Scope to search for and to apply optional regex to.
Required unless "find" is defined.
scope_filter: ([str] - default=[]): An array of scope qualifiers for the match.
Only used when "scope" is not defined.
- Any instance of scope qualifies match: scope.name
- Entire match of scope qualifies match: !scope.name
- Any instance of scope disqualifies match: -scope.name
- Entire match of scope disqualifies match: -!scope.name
greedy: (bool - default=True): Apply action to all instances (find all).
Used when "find" is defined.
greedy_scope: (bool - default=True): Find all the scopes specified by "scope."
format_replace: (bool - default=False): Use format string style replace templates.
Works only for Regex (with and without Backrefs) and Re (with Backrefs).
See https://facelessuser.github.io/backrefs/usage/#format-replacements for more info.
selection_inputs (bool -default=False): Use selection for inputs into find pattern.
Global setting "selection_only" must be disabled for this to work.
multi_pass: (bool - default=False): Perform multiple sweeps on the scope region to find
and replace all instances of the regex when regex cannot be formatted to find
all instances. Since a replace can change a scope, this can be useful.
plugin: (str): Define replace plugin for more advanced replace logic.
Only used for regex replaces and replace.
args: (dict): Arguments for 'plugin'.
Only used for regex replaces and replace.
Once you've defined replacements, there are a number of ways to run a sequence. One way is to create a command in the command palette by editing/creating a Default.sublime-commands in your User folder and then adding your command(s).
Basic replacement command:
{
"caption": "Reg Replace: Remove Trailing Spaces",
"command": "reg_replace",
"args": {"replacements": ["remove_trailing_spaces"]}
},
Chained replacements in one command:
{
"caption": "Reg Replace: Remove HTML Comments and Trailing Spaces",
"command": "reg_replace",
"args": {"replacements": ["remove_html_comments", "remove_trailing_spaces"]}
}
You can also bind a replacement command to a keyboard shortcut:
{
"keys": ["ctrl+shift+t"],
"command": "reg_replace",
"args": {"replacements": ["remove_trailing_spaces"]}
}
Selection Inputs
Experimental
This feature is experimental and is subject to change.
If selection_inputs is set to True, selections will be inserted into your pattern via format string logic.
So to specify two implicit variables, the following format string logic can be used: r'Some value {} some [\w]+ {}'. In this example, the first two selections will be inserted in {}: r'Some value selection0 some [\w]+ selection1'.
To control which selection goes where, you can explicitly set the index: r'Some value {1} some [\w]+ {0}' →. r'Some value selection1 some [\w]+ selection0'. Or alternatively: r'Some value {sel[1]} some [\w]+ {sel[0]}' (sel is the selection list).
By default, the selection is just inserted into the pattern raw. This is fine for literal searches, but for regex this is bad if your selection is something like: something(else). This example would be interpreted as adding a group containing else. So if this is not intended, the text would need to be escaped. So a new conversion type has been added to the format template: !e. This new conversion type will insert the selection into the pattern after first escaping it. So you could use it like so: r'Some value {1!e} some [\w]+ {0!e}', and the selection inputs would be escaped.
For the sake of avoiding bad situations, RegReplace will limit the length of selections to the arbitrary value of 256, but you can configure this with the global setting selection_input_max_size in reg_replace.sublime-settings. Also, the number of allowed inputs will be limited to 10, but this can be tweaked via the setting selection_input_max_count.
// Limit size of selections for inputs.
"selection_input_max_size": 256,
// Limit number of selections for inputs.
"selection_input_max_count": 10,
This should go without saying, but this is incompatible if you have the global option selection_only set which will search in selection content. Though you can ignore it per command via the command parameter no_selection. So if you are constructing a chain that uses selection inputs, you can temporarily disable it with no_selection.
A Better Way to Create Regex Rules
A new feature was recently added that allows editing regular expression rules in a panel with Python syntax highlighting, providing a friendlier editing experience. Users can even split their regular expressions on multiple lines and add comments which will be preserved the next time the rule is viewed.
While in the edit panel, you can press Ctrl+S on Windows/Linux (or Cmd+S on OSX) and the rule will be saved back to the settings file. On saving, the regex is compiled to test if it's valid; if the test fails, a warning message is displayed and the saving operation is canceled.
To edit, insert, or delete rules, you can use the following command palette commands:
- RegReplace: Edit Regular Expression Rule
- RegReplace: Create New Regular Expression Rule
- RegReplace: Delete Regular Expression Rule
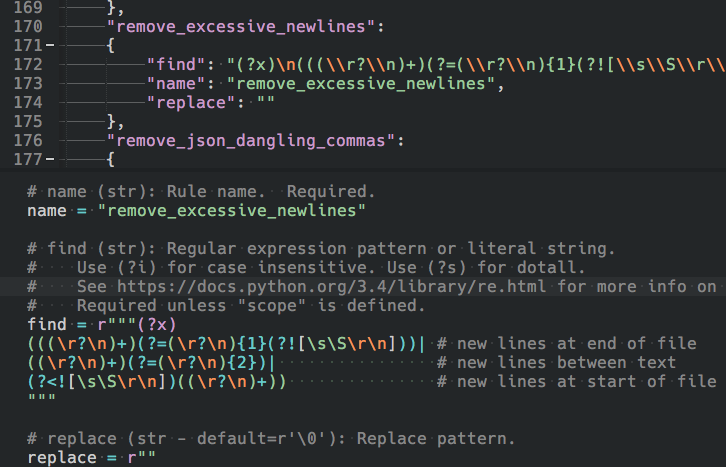
You can also test the regular expression from the edit panel. At the bottom of the panel, you should see the test variable which will allow you to configure a sequence to run from the panel. Once configured, you can press Ctrl+F on Windows/Linux (or Cmd+F on OSX) to execute it. Keep in mind that you can run the current rule sequenced together with others in the test configuration to test how it plays with other rules. test is not saved with the other settings, but is only good for the current session.
# ----------------------------------------------------------------------------------------
# test: Here you can setup a test command. This is not saved and is just used for this session.
# - replacements ([str]): A list of regex rules to sequence together.
# - find_only (bool): Highlight current find results and prompt for action.
# - action (str): Apply the given action (fold|unfold|mark|unmark|select).
# This overrides the default replace action.
# - options (dict): optional parameters for actions (see documentation for more info).
# - key (str): Unique name for highlighted region.
# - scope (str - default="invalid"): Scope name to use as the color.
# - style (str - default="outline"): Highlight style (solid|underline|outline).
# - multi_pass (bool): Repeatedly sweep with sequence to find all instances.
# - no_selection (bool): Overrides the "selection_only" setting and forces no selections.
# - regex_full_file_with_selections (bool): Apply regex search to full file then apply
# action to results under selections.
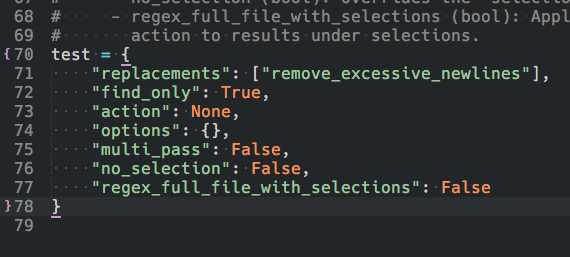
Depending on how the test command was configured, it may cause the panel to close, or you might accidentally close it by pressing Esc or running some other command. When closed, the currently opened rule is not lost and can be brought back by running the command palette command RegReplace: Show Edit Panel (the command will only work if the panel has been opened at least once). You can also use the panel icon in the bottom left hand corner of the Sublime Text window (only on later versions of Sublime Text 3).
View Without Replacing
If you would like to simply view what the sequence would find, without carrying out any replacements, (aka "dry run") you can construct a command to highlight targets without replacing them (each pass could affect the end result, but this just shows all passes without predicting the replacements).
Just add the "find_only" argument and set it to true.
{
"caption": "Reg Replace: Remove Trailing Spaces",
"command": "reg_replace",
"args": {"replacements": ["remove_trailing_spaces"], "find_only": true}
},
A prompt will appear allowing you to replace the highlighted regions. Regions will be cleared on cancel.
If for any reason the highlights do not get cleared, you can simply run the "RegReplace: Clear Highlights" command from the command palette.
Highlight color and style can be changed in the settings file.
Override Actions
If instead of replacing you would like to do something else, you can override the action. Actions are defined in commands by setting the action parameter. Some actions may require additional parameters be set in the options parameter. See examples below.
{
"caption": "Reg Replace: Fold HTML Comments",
"command": "reg_replace",
"args": {"replacements": ["remove_html_comments"], "action": "fold"}
},
{
"caption": "Reg Replace: Unfold HTML Comments",
"command": "reg_replace",
"args": {"replacements": ["remove_html_comments"], "action": "unfold"}
},
{
"caption": "Reg Replace: Mark Example",
"command": "reg_replace",
"args": {
"replacements": ["example"],
"action": "mark",
"options": {"key": "name", "scope": "invalid", "style": "underline"}
}
},
{
"caption": "Reg Replace: Unmark Example",
"command": "reg_replace",
"args": {
"action": "unmark",
"options": {"key": "name"}
}
},
Supported override actions
- fold
- unfold
- mark
- unmark
- select
Fold Override
"action": "fold"
This action folds the given find target. This action has no parameters.
Unfold Override
"action": "unfold"
This action unfolds the all regions that match the given find target. This action has no parameters
Mark Override
"action": "mark"
This action highlights the regions of the given find target.
Mark Options
Action options are specified with the options key.
Required Parameters
"options": {"key": "name"}
Unique name for highlighted regions.
Optional Parameters
"options": {"scope": "invalid"}
Scope name to use as the color. Default is invalid.
"options": {"style": "outline"}
Highlight style (solid|underline|outline). Default is outline.
Unmark Override
"action": "unmark"
This action removes the highlights of a given key. Replacements can be omitted with this command.
Unmark Options
Action options are specified with the options key.
Required Parameters
"options": {"key": "name"}
unique name of highlighted regions to clear
Select Override
"action": "select"
This action selects the regions of the given find target.
Multi-Pass
Sometimes it's not possible for a regular expression to find all instances in a single pass. In such cases, you can use the multi-pass option. This option will cause the repeated execution of the entire sequence until all instances are found and replaced. To protect against a poorly constructed multi-pass regular expression looping forever, there is a default max sweep threshold that will cause the sequence to kick out when reached. This threshold can be tweaked in the settings file.
Multi-pass is used in replaces and cannot be paired with override actions (it will be ignored), but it can be paired with find_only as find_only allows you to initiate a replace.
{
"caption": "Reg Replace: Remove Trailing Spaces",
"command": "reg_replace",
"args": {"replacements": ["example"], "multi_pass": true}
},
Replace Only Within Selection(s)
Sometimes you only want to search inside selections. This can be done by enabling the selection_only setting in the settings file. By enabling this setting, regular expression targets will be limited to the current selection if and only if a selection exists. Auto replace/highlight on save events ignore this setting. If you want a given command to ignore this setting, just set the no_selection argument to true. Highlight style will be forced to underline selections if find_only is set, to ensure they will show up.
// Ignore "selection_only" setting
{
"caption": "Reg Replace: Remove Trailing Spaces",
"command": "reg_replace",
"args": {"replacements": ["example"], "multi_pass": true, "no_selection": true}
},
Use Regular Expressions on Entire File Buffer When Using Selections
When selection_only is enabled, a regular expression chain might perform better by applying the regular expression on the entire file buffer and then pick the matches under the selections — as opposed to the default behavior of applying the regular expression directly to the selection buffer. This can be achieved via the regex_full_file_with_selections option:
{
"caption": "Remove: All Comments",
"command": "reg_replace",
"args": {
"replacements": [
"remove_comments", "remove_trailing_spaces",
"remove_excessive_newlines", "ensure_newline_at_file_end"
],
"find_only": true,
"regex_full_file_with_selections": true
}
},
Apply Regular Expressions Right Before File Save Event
If you want a sequence to be automatically applied before a file saves, you can define "on save" sequences in the reg_replace.sublime-settings file. Each "on save" sequence will be applied to the files matched by the file patterns or file regular expressions you specify. You must also set on_save to true. If you want the sequence to just highlight, fold, or unfold by regular expression, add the "action": "mark" key/value pair (supported values: mark|fold|unfold). Both types can be used at the same time. Actions are performed after replacements.
Example:
// If on_save is true, RegReplace will search through the file patterns listed below right before a file is saved,
// If the file name matches a file pattern, the sequence will be applied before the file is saved.
// RegReplace will apply all sequences that apply to a given file in the order they appear below.
"on_save": true,
// Highlight visual settings
"on_save_highlight_scope": "invalid",
"on_save_highlight_style": "outline",
"on_save_sequences": [
// An example on_save event that removes dangling commas from json files
// - file_regex: an array of regex strings that must match the file for the sequence to be applied
// - case: regex case sensitivity (true|false) false is default (this setting is optional)
// See https://docs.python.org/3.4/library/re.html for more information on Python's re.
// - file_pattern: an array of file patterns that must match for the sequence to be applied
// - sequence: an array of replacement definitions to be applied on saving the file
// - multi_pass: perform multiple passes on file to catch all regex instances
{
"file_regex": ["(?i).*\\.sublime-(settings|commands|menu|keymap|mousemap|theme|build|project|completions|commands)"],
"file_pattern": ["*.json"],
"sequence": ["remove_json_dangling_commas"]
},
// An example on_save_sequence that targets all files and highlights trailing spaces
// - file_pattern: an array of file patterns that must match for the sequence to be applied
// - sequence: an array of replacement definitions to be applied on saving the file
// - action: (mark|fold|unfold) instead of replace
{
"file_pattern": ["*"],
"sequence": ["remove_trailing_spaces"],
"action": "mark"
}
],
Custom Replace Plugins
There are times when simple regular expression replacements are not enough to get the job done. Since RegReplace uses Python's re regular expression engine, we can use Python code to intercept the replacement and carry out more complex tasks via a plugin. Because the plugins rely on Python's re, this will only apply to regular expression searches (not literal searches).
In this example we're going to search for dates in the YYYYMMDD format, and increment them by one day.
Below is the regular expression rule. Notice how we have defined a plugin to carry out replacement. Plugins are defined as if importing a Python module. In this example, we are loading it from the User package. You do not need an __init__.py file in rr_modules folder — and it's use is discouraged: Sublime shouldn't bother loading these files since RegReplace will load them when needed.
"date_up": {
"find": "(?P<year>\\d{4})(?P<month>\\d{2})(?P<day>\\d{2})",
"plugin": "User.rr_modules.date_up"
// "args": {"some_plugin_arguments": "if_desired"} <== optional plugin arguments
}
Next we can define the command that will utilize the regex rule:
{
"caption": "Replace: Date Up",
"command": "reg_replace",
"args": {"replacements": ["date_up"], "find_only": true}
},
Lastly, we provide the plugin. RegReplace will load the plugin and look for a function called replace. replace takes a python re match object, and any arguments you want to feed it. Arguments are defined in the regular expression rule as shown above.
SHORT_MONTH = 30
LONG_MONTH = 31
FEB_MONTH = 28
FEB_LEAP_MONTH = 29
JAN = 1
FEB = 2
MAR = 3
APR = 4
MAY = 5
JUN = 6
JUL = 7
AUG = 8
SEP = 9
OCT = 10
NOV = 11
DEC = 12
def is_leap_year(year):
return ((year % 4 == 0) and (year % 100 != 0)) or (year % 400 == 0)
def days_in_months(month, year):
days = LONG_MONTH
if month == FEB:
days = FEB_LEAP_MONTH if is_leap_year(year) else FEB_MONTH
elif month in [SEP, APR, JUN, NOV]:
days = SHORT_MONTH
return days
def increment_by_day(day, month, year):
mdays = days_in_months(month, year)
if day == mdays:
day = 1
if month == DEC:
month = JAN
year += 1
else:
month += 1
else:
day += 1
return day, month, year
def replace(m):
g = m.groupdict()
year = int(g["year"].lstrip("0"))
month = int(g["month"].lstrip("0"))
day = int(g["day"].lstrip("0"))
day, month, year = increment_by_day(day, month, year)
return "%04d%02d%02d" % (year, month, day)
Here is some text to test the example on:
# Test 1: 20140228
# Test 2: 20141231
# Test 3: 20140101
RegReplace ships with a simple example you can test with (/Packages/RegReplace/rr_modules/example.py). Because package control zips packages, it's hard to view its source directly, without using a plugin; therefore, I've pasted it below as well. Import it with "plugin": "RegReplace.rr_modules.example".
"""A simple example plugin."""
def replace(m, **kwargs):
"""Replace with groups."""
# pylint: disable=unused-argument
text = "Here are your groups: "
for group in m.groups():
if group is not None:
text += "(%s)" % group
return text
Regex Module
By default, RegReplace uses Python's re module. But if you prefer the
more advanced regex regular expression module, you can enable it with the
following setting:
// Use the regex module for regular expression.
// https://pypi.python.org/pypi/regex
"use_regex_module": true,
To select whether to use Version 0 or Version 1 of the regex module, simply change the following setting:
// When "use_regex_module" is enabled, select which version of the regex module to use (0 or 1).
// See documentation to understand the differences: https://pypi.python.org/pypi/regex.
"regex_module_version": 0,
Extended Back References
RegReplace uses a special wrapper around Python's re library called backrefs. Backrefs was written specifically for RegReplace and adds various additional backrefs that are known to some regular expression engines, but not to Python's re. Backrefs adds: \p, \P, \u, \U, \l, \L, \Q or \E (though \u and \U are replaced with \c and \C). It even adds some of the Posix style classes such as [:ascii:] etc.
Backrefs also works with the regex module, but it enables a smaller portion of back references as the regex module implements a few of the back references already (in one form or the other). For instance, there was no need to add Unicode properties as it was already available. And since you can already use Unicode and/or Posix properties for uppercase and lowercase character classes in search patterns, and regex already reserves \L, it wasn't worth the extra work to try and add equivalents for \c, \C, 'l' and \L to the search back references.
You can enable extended back references in the settings file:
// Use extended back references
"extended_back_references": true
When enabled, you can apply the back references to your search and/or replace patterns as you would other back references:
"test_case": {
"find": "([a-z])(?P<somegroup>[a-z]*)((?:_[a-z]+)+)",
"replace": "\\c\\1\\L\\g<somegroup>\\E\\C\\g<3>\\E",
"greedy": true
}
You can read more about the backrefs' features in the Backrefs' documentation.
Getting the Latest Backrefs
It is not always clear when Package Control updates dependencies. So to force dependency updates, you can run Package Control's Satisfy Dependencies command which will update to the latest release.
Using Backrefs in RegReplace Plugins
You can import backrefs into a RegReplace plugin:
from backrefs as bre
Or use bregex for the regex module with backrefs:
from backrefs as bregex
Backrefs does provide a wrapper for all of re's normal functions such as match, sub, etc., but it's recommended to pre-compile your search patterns and your replace patterns for optimal performance — especially if you plan on reusing the same pattern multiple times. Since re does cache a certain amount of the non-compiled calls, you'll be spared from some performance hit, but backrefs does not cache the pre-processing of search and replace patterns.
To use pre-compiled functions, you compile the search pattern with compile_search. If you want to take advantage of replace backrefs, you need to compile the replace pattern as well. Notice that the compiled pattern is fed into the replace pattern; you can feed the replace compiler the string representation of the search pattern as well, but the compiled pattern will be faster and is the recommended way.
pattern = bre.compile_search(r'somepattern', flags)
replace = bre.compile_replace(pattern, r'\1 some replace pattern')
Then you can use the complied search pattern and replace:
text = pattern.sub(replace, r'sometext')
… or:
m = pattern.match(r'sometext')
if m:
text = replace(m) # similar to m.expand(template)
To use the non-compiled search/replace functions, you call them just as you would in re; the names are the same. Methods like sub and subn will compile the replace pattern on the fly if given a string.
for m in bre.finditer(r'somepattern', 'some text', bre.UNICODE | bre.DOTALL):
# do something
If you want to replace without compiling, you can use the expand method.
m = bre.match(r'sometext')
if m:
text = bre.expand(m, r'replace pattern')